Media
What’s the difference between captioning and transcription?
26 Aug 2022
4 minute read
The audio-to-text world can be a confusing place. Should you be captioning your content or providing viewers with a transcript? Even when you decide on what will work best with your content, how should you go about creating the text? What even is the difference between captioning and transcription in the first place?
In this article, we’ll explain the difference between captioning and transcription, how to create captions and transcripts for your content, the benefits of audio-to-text for different industries, and which software to use.
The difference between captioning and transcription:
Transcription is the process of converting voice or audio into a written, plain text document. The transcript will not have any time information linked to it because it is the plain-text result of transcription.
Captioning is the act of splitting transcript text into chunks (known as “caption frames”) and time-coding each frame to synchronize with video audio. Output is often displayed at the bottom of a video screen and should always portray speech and sound effects, identify speakers, and account for any sound that is not visible. The transcript is used to make the caption.

Transform your audio and
video to text and subtitles
- High accurate, on demand service
- Competitive pricing with the fastest turnaround using AI
- Upload, search edit and export captions and transcripts with ease.
Transcription vs. Captioning in depth
What are transcriptions?
Transcription, also known as transcribing, is the process of transforming audio-to-text. When you have recorded content, whether it be audio or video, a transcript is essentially the audio written out in text format, including, who said what and at what time. Transcripts are useful for a variety of content like podcasts or research interviews.
There are two types of transcripts:
Verbatim: the text includes filler words such as uhh’s and erms, false starts, etc.
Clean read: the text has been edited slightly for readability, so it does not contain filler words or distractions.
The benefits of transcribing your content:
- It helps those who are deaf and hard of hearing experience your audio content. Your content will be more accessible and engaging to a wider audience.
- Transcripts greatly help your content rank in search engine results, and are an easy way to boost your SEO performance!
- Transcripts create a better user experience for non-native speakers or those who may not be able to listen to your content with the sound on.
- Having your audio transformed into text helps you find key fragments quickly, without having to listen repeatedly to the audio. This is beneficial to researchers and those who work in media and production.
What are captions?
Captions are the text version of the audio of a video, but they are shown on the video. Captions can be in the same language as the audio or they can be translated into other languages to help those who are not native speakers, understand the content.
Types of captions
Closed captions: These captions are in a separate file from the video and can be turned on or off by the viewer.
Open captions: Open captions are burned into the video and the viewer has no control over whether to turn them off.
The benefits of captioning your videos:
- Captions help those who are deaf and hard of hearing experience your content
- Subtitles help people who may not understand the language of the audio experience the content
- Captions help to improve the SEO value of content, as it makes the video readable to search engines
- Those who cannot listen to your videos out loud in public settings can still understand what is being said

How to easily create transcripts and captions:
Creating transcripts and captions by yourself can be a time-consuming and boring process. For every minute of audio, it can take over 8 minutes to fully transcribe!
That’s why there are professional captioning and transcription services out there that can help!
At Amberscript, we’re on a mission to make all audio accessible by making the process of transcribing and captioning content a lot easier to do. We use state-of-the-art Automatic Speech Recognition (ASR) software to create high-quality audio-to-text, fast!
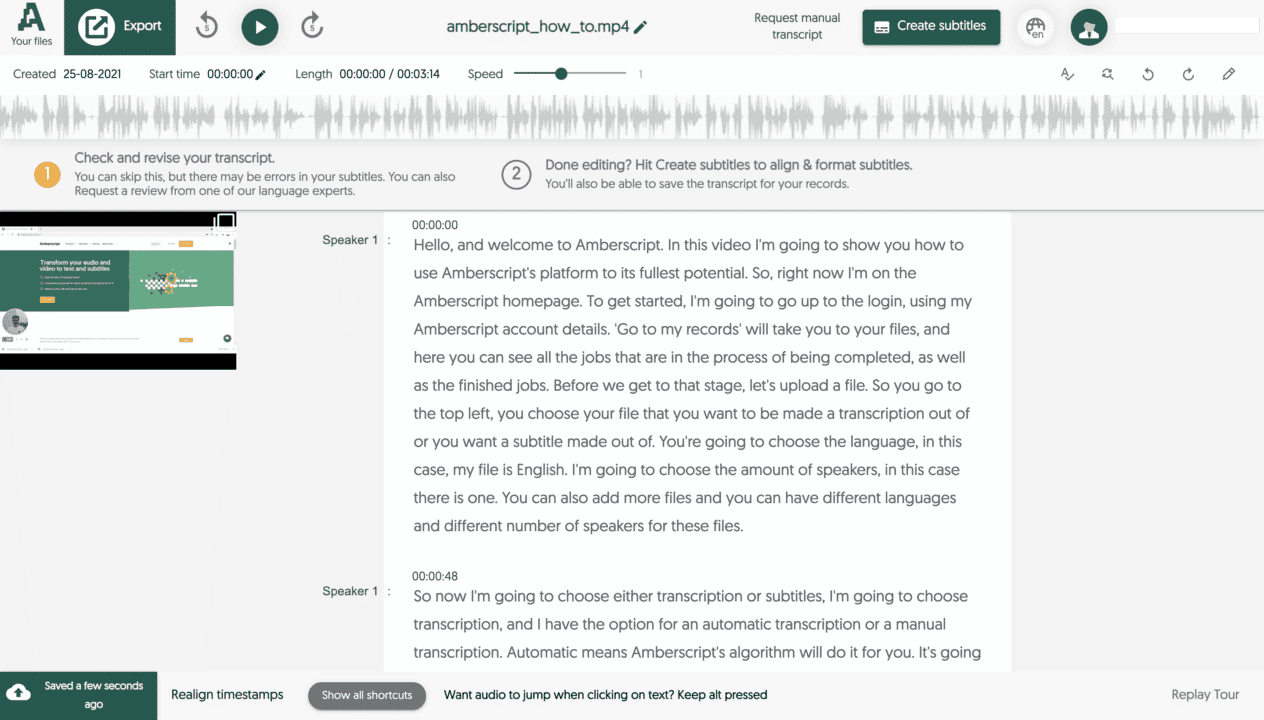
How to create captions and transcripts automatically with Amberscript:
- Start a free Amberscript account
- Upload your file(s)
- Choose whether you want subtitles or transcripts
- Select the audio’s language and how many speakers there are
- Choose your service:
- 5a. Human-made: Your content is created by professional transcribers and captioners. We handle the whole process, making sure that the text is 100% accurate.
- 5b. Machine-made: Your text is created automatically with our ASR. Depending on the audio quality of the file, the text will be up to 85% accurate. You can use our online editor to make changes to the text and perfect it as much as you like.
- 6. Export and share your file!